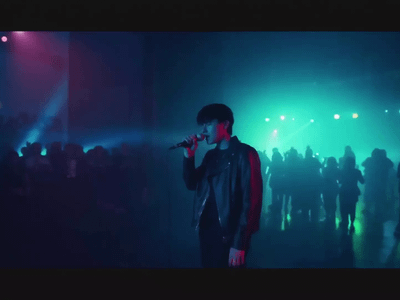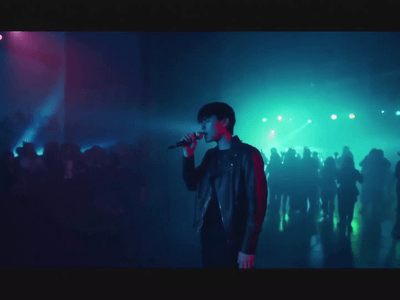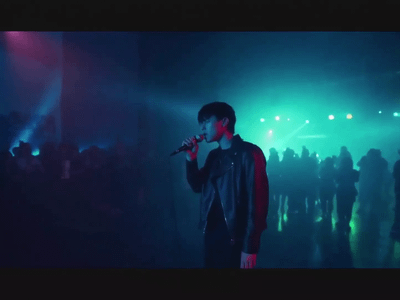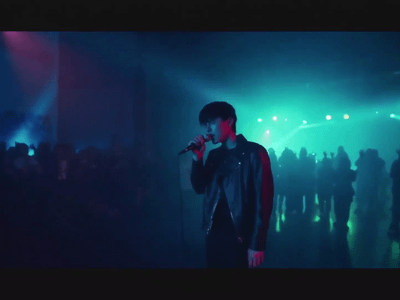Image to Talking Video - LTX 2.3 + ElevenLabs UGC
Api
Audio to Video
Ltx2.3
1
333




Nodes & Models
VLM_floyo
ElevenLabsTTS_floyo
LoadImage
MarkdownNote
PreviewAny
RegexExtract
SaveAudioMP3
SaveVideo
Drop in a portrait. Get back a UGC-style talking video where that character speaks a generated line on camera.
Gemini reads your image and writes both the script and the scene prompt. ElevenLabs voices the script. LTX 2.3 with a talkvid identity LoRA generates the video with lip sync built in.
Output: 9 seconds, 720x1280 vertical, 24fps. Tuned for Reels, TikTok, and Shorts.
How do you generate a UGC talking video from an image?
Upload a portrait, hit run. Gemini auto-writes a short script and a UGC-flavored scene description. ElevenLabs (default voice: Rachel) reads the script. LTX 2.3 with the talkvid LoRA produces a 9-second talking video. No prompts to write unless you want to override the auto-generated ones.
Input image A clear front-facing portrait of one person. Half-body or selfie framing works well. The talkvid identity LoRA preserves face and lip sync best when it has a clean reference, so avoid extreme angles, side profiles, or tiny faces in wide shots.
Voice Default: Rachel (ElevenLabs preset). Swap to any ElevenLabs voice by changing the voice name in the TTS node. Want your own voice? Enable the LoadAudio + ElevenLabs Instant Voice Clone nodes (bypassed by default), drop in around 30 seconds of clean audio, and the workflow uses your cloned voice for the dialogue.
Stability and similarity Defaults: stability 0.5, similarity 0.75. Want bigger emotional range and more dramatic delivery? Drop stability to 0.3. Want consistent, even reads (good for repeated use)? Push to 0.7. Higher similarity sticks closer to the reference voice.
VLM user prompt Default: "Create a short engaging talking video script from this image". Swap this if you want a different angle. Try "Write a product testimonial script" for ad creative, "Write a curious reaction line" for social hooks, or "Generate a tutorial intro" for educational content. Gemini still generates both the dialogue and scene parts.
System prompt (advanced) The Gemini system prompt is preset for UGC realism: handheld camera feel, direct-to-camera energy, casual creator delivery, capped near 10 seconds of speech. Edit it if you want a different feel like cinematic, broadcast, or scripted commercial.
Resolution and duration Default: 720x1280 vertical, 9 seconds at 24fps. The talkvid LoRA is tuned for vertical talking-head shots. Changing dimensions tends to hurt lip sync and identity stability.
LTX 2.3 settings The video subgraph runs ltx-2.3-22b-dev with the talkvid identity LoRA, a distilled speed LoRA, and a built-in spatial upscaler at 2x. These are pre-tuned for UGC talking head video. Most users leave them alone.
What is the image to talking video workflow good for?
Producing creator-style talking videos at scale: testimonial ads, product shoutouts, social hooks, tutorial intros, and concept pitches where you need a person on camera saying something specific. Useful when you have a still image (a brand model, a generated character, an existing avatar) and need video creative without booking talent or shooting.
The pipeline is built for short-form vertical content. The Gemini system prompt biases everything toward UGC realism: handheld framing, casual gestures, direct-to-camera delivery. The talkvid LoRA on LTX 2.3 keeps identity stable across the 9-second clip and handles lip sync without separate rigging.
Voice cloning is the underrated part. Drop in 30 seconds of someone speaking and the pipeline produces video using that voice. Useful for matching a brand voice, building consistent character voices across episodes, or making a generated character sound like a real person.
When to skip: producing a hero film spot? Cinematic AI workflows give you more directorial control. Need precise lip sync to existing audio? A dedicated lip sync workflow like LatentSync will land tighter sync.
FAQ
What kind of image works best for the LTX 2.3 talking video workflow? A clear front-facing portrait or half-body shot of one person. Selfie framing, eye contact with the camera, and good lighting on the face all help. The talkvid identity LoRA preserves the face better when it has a clean reference. Avoid extreme angles, heavy occlusion, or wide shots where the face is small.
Can I clone my own voice for the talking video? Yes. Enable the LoadAudio and ElevenLabs Instant Voice Clone nodes (both bypassed by default), upload around 30 seconds of clean audio, and the workflow uses your cloned voice for the generated dialogue. Useful for matching brand voice or producing consistent character voices across multiple videos.
How long is the output video and what aspect ratio? 9 seconds at 720x1280 vertical, 24fps. The duration is capped by the Gemini system prompt, which limits the spoken script to about 10 seconds of audio. The LTX 2.3 talkvid LoRA is tuned for vertical talking-head shots, so this format gives the best lip sync and identity stability.
Can I write my own dialogue instead of using the auto-generated script? Yes. The VLM auto-writes both the dialogue and the scene prompt from your image, but you can override either. Type your dialogue directly into the workflow if you have specific copy that has to land verbatim. Keep it under about 35 spoken words to fit in the 9-second window.
Does the LTX 2.3 talkvid workflow lip sync the character to the audio? Yes. LTX 2.3 with the talkvid identity LoRA handles lip sync as part of generation. It's not as tight as a dedicated lip sync model on existing footage, but for image-to-video with auto-generated audio it produces convincing speaking motion. Front-facing portraits with clear mouth visibility give the cleanest results.
How to run the image to talking video workflow online? You can run this LTX 2.3 + ElevenLabs pipeline online through Floyo. No installation, no setup. Open the workflow in your browser, upload your image, and hit run.
Read more